
checkpoint 检查点
作用
一般checkpoint会将某个时间点之前的脏数据全部刷新到磁盘,以实现数据的一致性与完整性。其主要目的是为了缩短崩溃恢复时间。
数据库靠谱的原因
一条DML 写入过程
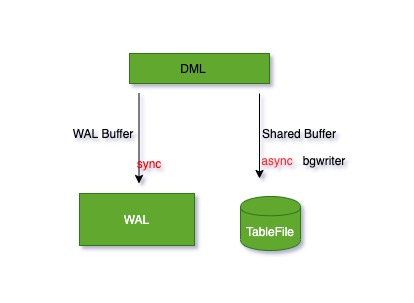
在写入数据的时,当事务提交后修改信息顺序同步写入wal。shared buffer中信息并不是马上落盘。异步同步磁盘。
这里实现双写:
| 位置 | 是否同步 | 方式 | 负责进程 |
|---|---|---|---|
| WAL | 同步 | 顺序写 | walwriter |
| TableFile | 异步 | 随机读写 | backgroudwriter |
即保障了数据的完整性又同时兼顾的性能。
意外发生时如何恢复
有了wal 可以保证数据的完整性,数据不丢失。那么具体该如何恢复?
因为产生wal是个顺序写的过程,只要回放wal就可重现写入过程。如重现一个一摸一样的从库。
首先要确定一个问题就是当前数据库状态下应该从那个具体位置开始回放。 这里就需要checkpoint。
这个具体位置(检查点)之前的数据已经同步到数据库,之后的数据要么在缓存中的脏数据,要么可能意外丢失。
检查点可作为清理WAL的依据,从而避免WAL日志堆积。
Checkpoint 具体工作
- 记录检查点的开始位置,记录为 redo point(重做位点)
- 将 shared buffer 中的数据刷到磁盘里面去
- 刷脏结束,检查点之前的数据均已被刷到磁盘存储(数据1和2)
- 记录相关信息
- 将最新的检测点记录在 pg_control 文件中
触发条件
- 超级用户(其他用户不可)执行CHECKPOINT命令
- 数据库shutdown
- 数据库recovery完成
- XLOG日志量达到了触发checkpoint阈值
- 周期性地进行checkpoint,周期内无写入不执行checkpoint
- 需要刷新所有脏页
相关参数
Postgresql 10
# - Checkpoints -
checkpoint_timeout = 5min # range 30s-1d
max_wal_size = 2GB
min_wal_size = 1GB
checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
- checkpoint_segments WAL log的最大数量,系统默认值是3。超过该数量的WAL日志,会自动触发checkpoint。 新版(9.6)使用min_wal_size, max_wal_size 来动态控制wal日志
- checkpoint_timeout 系统自动执行checkpoint之间的最大时间间隔。系统默认值是5分钟。
- checkpoint_completion_target 该参数表示checkpoint的完成时间占两次checkpoint时间间隔的比例,系统默认值是0.5,也就是说每个checkpoint需要在checkpoints间隔时间的50%内完成。
- checkpoint_warning 系统默认值是30秒,如果checkpoints的实际发生间隔小于该参数,将会在server log中写入一条相关信息。可以通过设置为0禁用。
记录日志
参数配置开启
log_checkpoints = on
日志信息
restartpoint complete: wrote 12166 buffers (0.6%); 0 WAL file(s) added, 0 removed, 0 recycled; write=269.888 s, sync=0.002 s, total=269.892 s; sync files=489, longest=0.001 s, average=0.001 s; distance=156927 kB, estimate=156927 kB
recovery restart point at 204F/41B7840","last completed transaction was at log time
通过 pg_stat_bgwriter 视图查看
select checkpoints_timed,checkpoints_req,checkpoint_write_time,buffers_checkpoint,buffers_clean from pg_stat_bgwriter ;
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 7
checkpoints_req | 0
checkpoint_write_time | 1619504
checkpoint_sync_time | 125
buffers_checkpoint | 190388
buffers_clean | 13574
应用
预防wal写放大
如何判断是否需要优化WAL?
wal 文件名组成
- timeline 8位
- 逻辑号 8位
- 偏移量
与wal_lsn对应关系查看
postgres=# select pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
5A/AD000000
(1 行记录)
postgres=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
000000020000005A000000AC
关于如何判断是否需要优化WAL,可以通过分析WAL,然后检查下面的条件,做一个粗略的判断:
- FPI比例高于70%
- HOT_UPDATE比例低于70%
FPI及HOT_UPDATE查看方法
/usr/pgsql-10/bin/pg_waldump --stats=record -p /var/lib/pgsql/10/data/pg_wal/ -t 2 -s 15/56098120 -e 15/56098200
-z 统计信息
-p wal path
-t timeline
-s sart lsn
-e end lsn
获取wal lsn psql -c "checkpoint;select pg_current_wal_lsn"
/usr/pgsql-10/bin/pg_waldump --stats=record -s 1095/90000000 -e 1098/70000000 -t 3
Type N (%) Record size (%) FPI size (%) Combined size (%)
---- - --- ----------- --- -------- --- ------------- ---
XLOG/CHECKPOINT_ONLINE 107 ( 0.00) 11342 ( 0.00) 0 ( 0.00) 11342 ( 0.00)
XLOG/NEXTOID 2 ( 0.00) 60 ( 0.00) 0 ( 0.00) 60 ( 0.00)
XLOG/FPI 1 ( 0.00) 49 ( 0.00) 64 ( 0.00) 113 ( 0.00)
Transaction/COMMIT 2541235 ( 3.27) 86401990 ( 1.44) 0 ( 0.00) 86401990 ( 0.71)
Transaction/ABORT 462 ( 0.00) 15708 ( 0.00) 0 ( 0.00) 15708 ( 0.00)
Transaction/COMMIT 1337 ( 0.00) 181730 ( 0.00) 0 ( 0.00) 181730 ( 0.00)
Storage/CREATE 3 ( 0.00) 126 ( 0.00) 0 ( 0.00) 126 ( 0.00)
Storage/TRUNCATE 3 ( 0.00) 138 ( 0.00) 0 ( 0.00) 138 ( 0.00)
CLOG/ZEROPAGE 78 ( 0.00) 2340 ( 0.00) 0 ( 0.00) 2340 ( 0.00)
CLOG/TRUNCATE 1 ( 0.00) 38 ( 0.00) 0 ( 0.00) 38 ( 0.00)
Standby/LOCK 5 ( 0.00) 210 ( 0.00) 0 ( 0.00) 210 ( 0.00)
Standby/RUNNING_XACTS 2165 ( 0.00) 115914 ( 0.00) 0 ( 0.00) 115914 ( 0.00)
Standby/INVALIDATIONS 653 ( 0.00) 73814 ( 0.00) 0 ( 0.00) 73814 ( 0.00)
Heap2/CLEAN 3212348 ( 4.13) 394164646 ( 6.58) 308907392 ( 4.97) 703072038 ( 5.76)
Heap2/FREEZE_PAGE 4 ( 0.00) 261 ( 0.00) 3776 ( 0.00) 4037 ( 0.00)
Heap2/CLEANUP_INFO 357 ( 0.00) 14994 ( 0.00) 0 ( 0.00) 14994 ( 0.00)
Heap2/VISIBLE 231176 ( 0.30) 13640564 ( 0.23) 1933312 ( 0.03) 15573876 ( 0.13)
Heap/INSERT 2746943 ( 3.53) 475090632 ( 7.93) 367845268 ( 5.92) 842935900 ( 6.91)
Heap/DELETE 2744490 ( 3.53) 148841990 ( 2.48) 886729344 ( 14.27) 1035571334 ( 8.48)
Heap/UPDATE 382906 ( 0.49) 32082700 ( 0.54) 73490712 ( 1.18) 105573412 ( 0.86)
Heap/HOT_UPDATE 59903887 ( 77.09) 4253014469 ( 71.00) 104818576 ( 1.69) 4357833045 ( 35.70)
Heap/LOCK 357336 ( 0.46) 19298469 ( 0.32) 2406840 ( 0.04) 21705309 ( 0.18)
Heap/INPLACE 1887 ( 0.00) 305288 ( 0.01) 1981592 ( 0.03) 2286880 ( 0.02)
Heap/INSERT+INIT 1467 ( 0.00) 2120913 ( 0.04) 0 ( 0.00) 2120913 ( 0.02)
Heap/UPDATE+INIT 2 ( 0.00) 445 ( 0.00) 0 ( 0.00) 445 ( 0.00)
Btree/INSERT_LEAF 5397231 ( 6.95) 415152935 ( 6.93) 4231482284 ( 68.08) 4646635219 ( 38.07)
Btree/INSERT_UPPER 34770 ( 0.04) 2824004 ( 0.05) 125457032 ( 2.02) 128281036 ( 1.05)
Btree/SPLIT_L 4589 ( 0.01) 18282344 ( 0.31) 12146020 ( 0.20) 30428364 ( 0.25)
Btree/SPLIT_R 30544 ( 0.04) 117070220 ( 1.95) 47733540 ( 0.77) 164803760 ( 1.35)
Btree/DELETE 9838 ( 0.01) 2622892 ( 0.04) 2366804 ( 0.04) 4989696 ( 0.04)
Btree/UNLINK_PAGE 14014 ( 0.02) 1262698 ( 0.02) 39943120 ( 0.64) 41205818 ( 0.34)
Btree/NEWROOT 1 ( 0.00) 78 ( 0.00) 0 ( 0.00) 78 ( 0.00)
Btree/MARK_PAGE_HALFDEAD 14014 ( 0.02) 1038026 ( 0.02) 364100 ( 0.01) 1402126 ( 0.01)
Btree/VACUUM 39493 ( 0.05) 3974383 ( 0.07) 8039632 ( 0.13) 12014015 ( 0.10)
Btree/REUSE_PAGE 27138 ( 0.03) 1248348 ( 0.02) 0 ( 0.00) 1248348 ( 0.01)
Gin/UPDATE_META_PAGE 52 ( 0.00) 9476 ( 0.00) 144256 ( 0.00) 153732 ( 0.00)
Gin/INSERT_LISTPAGE 1 ( 0.00) 358 ( 0.00) 0 ( 0.00) 358 ( 0.00)
Sequence/LOG 9093 ( 0.01) 900207 ( 0.02) 0 ( 0.00) 900207 ( 0.01)
-------- -------- -------- --------
Total 77709633 5989764799 [49.07%] 6215793664 [50.93%] 12205558463 [100%]
以上仅仅是粗略的经验值,仅供参考。并且这个FPI比例可能不适用于低写负载的系统,低写负载的系统FPI比例一定非常高,但是,低写负载系统由于写操作很少,因此FPI比例即使高一点也没太大影响。
优化WAL及副作用
-
延长checkpoint时间间隔 导致crash恢复时间变长。crash恢复时需要回放的WAL日志量一般小于max_wal_size的一半,WAL回放速度(wal_compression=on时)一般是50MB/s~150MB/s之间。可以根据可容忍的最大crash恢复时间,估算出允许的max_wal_size的最大值。
-
调整fillfactor 过小的设置会浪费存储空间,这个不难理解。另外,对于频繁更新的表,即使把fillfactor设成100%,每个page里还是要一部分空间被dead tuple占据,不会比设置成一个合适的稍小的fillfactor更节省空间。
-
设置wal_compression=on 需要额外占用CPU资源进行压缩,但影响不大
http://www.postgres.cn/news/viewone/1/273
更多细节说明
https://yq.aliyun.com/articles/582847
原理